Hook scripts
Introduction
The Modern UI allows you to insert hook scripts at certain stages of the search process. These hook scripts allow you to perform actions over the input parameters before the query is submitted to the query processor or transform the results after the query has been run but before the results are displayed to the user.
The hook scripts must be written in the Groovy programming language. Groovy runs on top of the Java Virtual Machine and offers the same power of Java classes but with more flexibility. The hook scripts will be automatically re-compiled when a change is detected in them.
Search process / lifecycle
When a query is submitted to Funnelback it passes through a series of steps between the initial submission, building of the data model question to the actual running of the query, processing of the result packet before the final result is delivered to the end user.
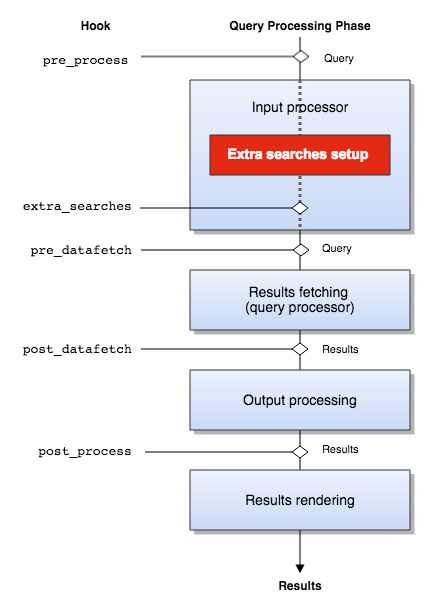
Each step of this lifecycle has a corresponding hook allowing manipulation of the data model using the corresponding user interface hook script.
The search lifecycle runs the following phases:
- A query is submitted on a specific collection and passes an input processing phase. This phase will configure any relevant parameter depending on the collection configuration, apply faceted navigation constraints, transform some meta_* or query_* parameters into query expressions, etc.
- Extra searches (if any) are prepared, cloning the environment from the main search.
- Once the input parameters have been prepared the search results are fetched, both for the main search and the extra searches. The query processor is run with the input parameters and return results.
- The results then passes an output processing phase. This phase will transform the result data according to the configuration, apply click tracking URLs, generate faceted navigation data from the metadata counts, etc.
- Once the results have been transformed and the data model is ready, it's passed to FreeMarker which will render the search results page.
Hook scripts
The following five hook points are provided as part of the search lifecycle. A corresponding hook script can be run at each of these points, allowing manipulation of the data model at the current state in the lifecycle.
Understanding the state of the data model at every step in the process is key to writing an effective hook script.
Hook scripts need to be defined on the collection that is being queried.
The most commonly used hook scripts are the pre and post process hooks.
-
Pre-process: (
hook_pre_process.groovy) This runs after initial question object population, but before any of the input processing occurs. Manipulation of the query and addition or modification of most question attributes can be made at this point.Example uses: modify the user’s query terms; convert a postcode to a geo-coordinate and add geospatial constraints
-
Extra searches: (
hook_extra_searches.groovy) This runs after the extra search question is populated but before any extra search runs allowing modification of the extra search’s question.Example uses: add additional constraints (such as scoping) to the extra search.
-
Pre-datafetch: (
hook_pre_datafetch.groovy) This runs after all of the input processing is complete, but just before the query is submitted. This hook can be used to manipulate any additional data model elements that are populated by the input processing. This is most commonly used for modifying faceted navigation.Example uses: Update metadata, gscope or facet constraints.
-
Post-datafetch: (
hook_post_datafetch.groovy) This runs immediately after the response object is populated based on the raw XML return, but before other response elements are built. This is most commonly used to modify underlying data before the faceted navigation is built.Example uses: Rename or sort faceted navigation categories, modify live URLs
-
Post-process: (
hook_post_process.groovy) This is used to modify the final data model prior to rendering of the search results.Example uses: clean titles; load additional custom data into the data model for display purposes.
An addition hook script is available for working with cached documents.
- pre-cache: (
hook_pre_cache.groovy) This is used to modify the cached document prior to display.
Creating hook scripts
The hook scripts for a collection must be created in the collection configuration directory (they can be created using the file-manager).
Hook scripts immediately take effect as soon as they're present in a collection's configuration directory. Any changes in them will be immediately taken into account.
Writing hook scripts
Search lifecycle hook scripts
The hook scripts have access to the same data model as the template files. If you're already comfortable with writing search forms for the Modern UI using FreeMarker, writing hook scripts shouldn't be difficult.
The only difference reside in accessing the root data model objects like question and response. While they're directly available as is from a FreeMarker template, in hook scripts they're grouped under a transaction root object. So for example if you need to access the ID of the collection being searched you must use:
transaction.question.collection.id
The hook scripts doesn't need to implement a specific interface or to have a specific header. You can start writing the body of your script within the first line of the .groovy file. For example the following 1-line hook script appends "cat" to the user submitted query:
transaction.question.query += " cat"
Collection, profile and query parameters
The collection, profile and query parameters within the search question can be read from various spots (such as the various input parameter maps) in the data model. These parameters should be accessed from the following parameters as they will always be defined:
- Collection:
transaction.question.collection.id - Profile:
transaction.question.profile - Query:
transaction.question.query
Manipulating the data model from a hook script
When a query is submitted to Funnelback it runs through a query processing pipeline. This pipeline has several phases that initialise different elements within the data model.
The various hook scripts allow modification of the data model object at various points in the processing pipeline.
Manipulating the search question
The question can be manipulated using the following hook scripts:
- Pre process (
hook_pre_process.groovy) - Pre data fetch (
hook_pre_datafetch.groovy) - Extra searches (
hook_extra_searches.groovy)
The following is defined at the start of the processing:
question.rawInputParametersquestion.inputParameterMapquestion.additionalParametersquestion.environmentVariablesquestion.collectionquestion.profile- lang related elements
question.location
The pre process hook then runs. This can be used to modify or inject extra elements.
The following data model elements are populated after the pre process hook runs. Most of these will be setup depending on the raw input parameters.
sessionquestion.userKeys- faceted navigation related elements
question.metaParametersquestion.systemMetaParameters- curator related elements
- quicklinks related elements
- explore related elements
- extra search elements
The extra searches hook runs (this initialises all the extra search questions in the data model). Use this to modify the extra search questions.
The pre datafetch hook runs just before the query is passed to padre. This can modify elements that were generated after the pre process hook ran.
Key question data model items to modify
These items can be modified in the hook scripts. The decision on which hook script to use will depend on what you need to affect in the data model.
Modify in the pre process set if you want to affect how subsequent items are initialised (e.g. if you wish to change the meta parameters you can modify the meta_X values in the question.awInputParameters as a pre process step and this will mean that the question.metaParameters is generated correctly).
question.rawInputParameters
(and question.inputParameterMap)
Note: these two elements are different views of the same thing. question.inputParameterMap can be used if there is only a single value for the item (e.g. question.inputParameterMap["key"] = "value"). Otherwise you must use question.rawInputParameters. (e.g. question.rawInputParameters["key"] = ["value"] or question.rawInputParameters["key"] = ["value1","value2"])
Modify this for any parameters that will be used by the modern UI, or for any parameters that are used to setup the elements that are populated between the pre process hook and the extra searches/pre datafetch hooks
question.additionalParameters
Modify this for any parameters that need to be passed directly to padre as query processor options.
This includes the following:
originmaxdistsort- numeric query parameters (e.g.
lt_x) SMSFnum_ranks
question.query
Modify this if you need to manipulate the passed in query.
Manipulating the search response
The question can be manipulated using the following hook scripts:
- Post data fetch (
hook_post_datafetch.groovy) - use this to modify the raw response values returned by padre. e.g. to update the live URL before the click link is generated, or to make modifications to faceted navigation such as renaming or sorting categories. - Post process (
hook_post_process.groovy) - use this to makey any other modification to elements that will be displayed.
The initial response object is populated
The post data fetch hook runs.
The following is then initialised
- search result links (click, cache, final live and display links)
- curator related items
- html encoded summaries
- extra search responses
- related document elements
- faceted navigation elements
- translations
- search history
The post process hook runs.
Cache hook scripts
Because the pre_cache hook script doesn't run in the context of a search transaction, the data model is slightly different. Please consult the cached copies documentation for more details.
Debugging hook scripts
Compilation problems
If your script doesn't compile for any reason the error will be logged in the Modern UI log file: $SEARCH_HOME/web/logs/modernui.(Public/Admin).log.
The most common compilation problems are:
- Syntax errors.
- Typos when accessing the data model, such as using
transaction.question.colectioninstead oftransaction.question.collection.
Message logging
If you need to log messages from within your hook script you can do so by using an logger object. A logger object has a name and can log messages with various severity levels (debug, warn, info, error or fatal). To use a logger object from within your script use the following code:
def logger = org.apache.logging.log4j.LogManager.getLogger("com.funnelback.MyHookScript")
...
logger.info("The query is: " + transaction.question.query);
...
logger.fatal("No results were found")
The log messages will be written in one the Modern UI log files:
$SEARCH_HOME/web/logs/modernui.[Public/Admin].log.$SEARCH_HOME/data/<collection>/log/modernui.[Public/Admin].log(Linux)$SEARCH_HOME/web/logs/modernui.<collection>.[Public/Admin].log(Windows)
Note: The default configuration of log messages is set to output the error level of above, except for the loggers belonging to the com.funnelback namespace which output info messages. That mean that your messages won't appear unless:
- You use
logger.error()orlogger.fatal() - You use
logger.info()and your logger belongs to the Funnelback namespace:def logger = org.apache.logging.log4j.LogManager.getLogger("com.funnelback.MyHookScript")
The logging configuration and levels for the Modern UI can be edited in $SEARCH_HOME/web/conf/modernui/log4j.properties.
Examples
Please consult the data model documentation if you're not familiar with the data model contents (question, response, resultPacket, etc.).
Transforming each result
This example iterates over each result and changes the host name on each live URL using a regular expression. This is a post_datafetch hook because it should happen before the URLs are updated with click tracking information during the output phase.
transaction?.response?.resultPacket?.results.each() {
// In Groovy, "it" represents the item being iterated
it.liveUrl = (it.liveUrl =~ /www.badhost.com/).replaceAll("www.correcthost.com")
}
Processing additional input parameters
This example takes a country query string parameter and applies a query constraint on the p metadata class if it exists. Calling http://server.com/s/search?collection=test&query=travel&country=Australia will result in the query travel |p:"Australia" being run.
It's a pre_process hook because it should be run before the meta_* parameters are transformed to query expressions during the input phase.
def logger = org.apache.logging.log4j.LogManager.getLogger("com.funnelback.hooks.CountryParamHook")
def q = transaction.question
// Set the input parameter 'meta_p_phrase_sand' to the value
// of the 'country' query string parameter, if it exist
if (q.inputParameterMap["country"] != null) {
q.inputParameterMap["meta_p_phrase_sand"] = q.inputParameterMap["country"]
logger.info("Applied country constraint: " + q.inputParameterMap["country"])
}
Alternatively it could be done as a pre_datafetch hook by providing directly a query expression:
if (q.inputParameterMap["country"] != null) {
q.metaParameters.add("|p:\"" + q.inputParameterMap["country"] + "\"")
}
Transforming results metadata
This script takes the value of the d and t metadata, concatenates them and put them in the x metadata, for each result. It can be either a post_datafetch or a post_process hook since it doesn't depend on any transformation done in the output phase.
transaction?.response?.resultPacket?.results.each() {
// In Groovy, "it" represents the item being iterated
if (it.metaData["d"] != null && it.metaData["t"] != null) {
it.metaData["x"] = "Document " + it.metaData["t"] + " created on: " + it.metaData["t"]
}
}
Modifying an extra search query
This script modify an extra search to update its query with a metadata constraint. The resulting query expression for this extra search will be <original query> a:shakespeare. This example needs to be in a extra_searches hook since it needs to be run just before the extra search is actually submitted.
if ( transaction.extraSearchesQuestions["myExtraSearch"] != null ) {
def searchQuestion = transaction.extraSearchesQuestions["myExtraSearch"]
searchQuestion.query += " a:shakespeare"
}
This hook makes use of the extraSearchesQuestion data model node which contains a SearchQuestion object per configured extra search.
Transforming CGI parameters
Hook scripts can be used to perform CGI parameter transformations. The following example will change the gscope1 parameter depending on the selected form:
if (transaction.question.inputParameterMap["form"] == "scoped") {
transaction.question.inputParameterMap["gscope1"] = "12"
}
This is equivalent to the following CGI Transform:
form=scoped => gscope1=12
Pre-selecting a facet
Pre-selecting a facet is done by injecting the relevant query string parameter in the question. This needs to be done in the pre_process hook script so that the injected parameters are transformed in the relevant query constraints before the query processor is called:
transaction.question.inputParameterMap["f.Location|X"] = "Canberra"
If you want to pre-select two categories simultaneously for a single facet you must use rawInputParameters which allow multiple values to be set (See the data model documentation for more details about inputParameterMap and rawInputParameters:
transaction.question.rawInputParameters["f.Location|X"] = ["Canberra", "Sydney" ]
The syntax of the parameter is f.<FacetName>|<constraint>=<value> where FacetName and constraint are defined in your faceted navigation configuration. The constraint is either a metadata class name such as X, Y, ... or a gscope number, for example f.Color|1=red.
Query another collection and process the transaction
To perform extra searches using the built in feature is recommended, however you might want to perform an additional query manually for various reasons, such as running an extra query for each result of the main search. To do so you need to fire an HTTP request to the Modern UI and transform the resulting XML into Groovy objects.
import com.funnelback.publicui.xml.SearchXStreamMarshaller
def logger = org.apache.logging.log4j.LogManager.getLogger("com.funnelback.RequestModernUIHookScript")
// Create instance of utility class that will transform our XML back into Java/Groovy objects
def marshaller = new SearchXStreamMarshaller()
// Initialise the marshaller
marshaller.afterPropertiesSet()
// Request the XML for the additional search
// Beware of *not* requesting the same collection or it will get stuck in an infinite loop
def extraTransaction
new URL("http://localhost:8080/s/search.xml?collection=funnelback_documentation&query=best").withInputStream {
// Unmarshal the XML into a transaction object
stream -> extraTransaction = marshaller.unmarshalInputStream(stream)
}
// Put the extra transaction in the customData map
transaction.response.customData["mySearch"] = extraTransaction
Read values from a custom configuration file
This example makes use of the Java .properties format. First define your configuration in SEARCH_HOME/conf/<collection>/myConfig.properties:
results.titleSuffix=Suffix
postcode.2000=Sydney
postcode.3000=Melbourne
Then use the following hook script:
def props = new Properties()
new File(transaction.question.collection.configuration.configDirectory, "myConfig.properties").withInputStream {
stream -> props.load(stream)
}
transaction?.response?.resultPacket?.results.each() {
// Append suffix to title
it.title = it.title + props["results.titleSuffix"]
// Put city name in Z from postcode metadata in X
it.metaData["Z"] = props["postcode."+it.metaData["X"]]
}