Trimpush (HP TRIM/Records manager) collections
Introduction
TRIM is an electronic document/records management system. Funnelback can index the documents and records held by TRIM. Records from the TRIM database are regularly extracted and the contents of electronic documents are filtered and indexed. Results displayed in a web browser can then be linked back into the TRIM client software or optionally linked directly to the electronic documents themselves (See the section on extra collection options below). The TRIM adapter is only available when Funnelback is installed on a Microsoft Windows operating system.
TRIM repositories are gathered by a trim-push collection, which will insert records into an associated push collection.
Note that TRIMPush collections are compatible with TRIM v7 and above.
Note: Crawling large TRIM repositories usually require increasing the memory settings from the defaults, for the filtering service and jetty. This can be done in SEARCH_HOME/services/daemon.service and SEARCH_HOME/services/jetty-webserver.service by locating the line containing the -Xmx...m setting. A good starting point would be to use 512 MB for the filtering service, and 1.5GB for Push collections.
System setup
In order to "crawl" the TRIM database, the Funnelback crawler needs to be able to access TRIM. This involves:
- Installing the TRIM client and SDK onto the Funnelback server.
- Creating a TRIM user to query the database.
To install the TRIM client and SDK, see your relevant TRIM documentation (Note: Starting from TRIM 7.1, the SDK is automatically installed, there is no need to check a specific option in the installer).
TRIM users are normal Windows domain users that have been given specific access rights within TRIM. The Funnelback TRIM adapter must be able to login to TRIM to gather its content. For this purpose it is highly recommended that a specific Windows user be created to do this. This way, that user can be given the exact access rights that it needs within TRIM to gather the required content.
A Funnelback TRIM user will typically not need update permissions. (If you wish to gather all content from TRIM, then giving the Funnelback TRIM user administrator privileges will increase the speed of the gathering process). Your TRIM administrator should be able to assist with this. It is important to test that this user can login to TRIM from the Funnelback server -- use the TRIM client to verify that this works.
You also need to ensure that Domain Users are given access to the TRIM SDK's temporary folders on the Funnelback server. These folders are named ServerData and ServerLocalData and usually found under C:\Program Files (x86)\Hewlett-Packard\HP TRIM.
64bit systems
Depending on the version of TRIM, it may be necessary to install the 32bit version of the TRIM client even on 64bit systems to provide access to the API it provides.
TRIM Working folder
Since the TRIM client by default caches any documents it obtains from the TRIM server on the local machine, you must also switch off document caching in the TRIM client. Failing to do so will result in using twice the required amount of data space on your Funnelback server. To switch off caching, start your TRIM client as the Funnelback user, then navigate to: Tools → options → store caching and clear the checkbox.
Moreover you can set an alternate temporary directory than the default one, which is usually located on the C: drive inside the TRIM program folder. To do so, add a new registry String value named WebServerWorkPath in the following registry key:
HKLM\SOFTWARE\Wow6432Node\TOWER Software\TRIM5\
Set the value to the full path to the temporary directory, for example D:\Data\TRIM\WebServerWorkPath.
Creating a TRIMPush collection
TRIMPush collections store their data in a Push collection, so a Push collection must first be created and the indexer_options for the collection must be updated to include the -forcexml option to ensure trim records are interpreted as XML.
It it also recommended to customise the metadata mappings for this collection to better suit TRIM records.
The TRIMPush collection itself can then be created, and the id of the previous push collection should be set as the value of the trim.push.collection configuration setting.
The other key configuration properties to configure are:
Database ID
trim.database should be set to the two-alphanumeric ID for the TRIM database.
TRIM Workgroup Server
trim.workgroup_server should be set to the name of your TRIM server.
TRIM Workgroup Server Port
trim.workgroup_port should be set to the TCP port your TRIM server operates on.
Domain name, Username, Password
trim.domain, trim.user and trim.passwd should be set to the respective credentials of the TRIM crawling user.
Gather documents beginning from
trim.gather_start_date should be set to the date (in the format 1970-01-01 00:00) after which documents registered or modified will be gathered.
Stop gathering at
trim.gather_end_date should be set to the date (in the same format as above) where gathering it to stop. If blank the crawler will gather everything up to the most recent record.
Select records on
trim.gather_mode configures whether to select records based on their registration date (First time they were checked-in TRIM), their creation date (date of the file creation of the binary attachment of a record) or their last updated date (date of the latest modification in TRIM). Usually the former is selected for the initial crawl to retrieve all the content, then for daily updates it's switched to the latter.
Document types
trim.extracted_file_types configures the file types to be extracted from the database. Note that records without electronic documents can still be gathered as well.
Request delay
trim.request_delay is the time, in milliseconds, between requests for records.
Num. of threads
trim.threads is the number of simultaneous connections to the TRIM server. See trim.threads (collection.cfg) for more details and gather.slowdown.threads (collection.cfg) to setup a throttle schedule.
Time span, Time span unit
trim.timespan and trim.timespan.unit specify how the date range to gather should be split (See below for explanation).
Target push collection
trim.push.collection sets the Push collection to use to store records.
Overview of the crawl process
The TRIMPush gatherer usually crawls backward: It will start crawling records created today (or specified in the Stop gathering at setting) and work its way to the Gather documents beginning from date. This is to have the most recently created documents available for searching first.
Date range
The date range to gather is usually large on the very first crawl (for example from 2000 to today). In order to speed up the crawl and improve reliability the crawler will split this date range in smaller chunks: This is what the Time span and Time span unit settings are for. Using a smaller time span will make selecting records faster but will cause the selection to happen more frequently. The best setting is dependent of the TRIM server capacity and the number of record to gather.
Checkpoints
The crawler creates a checkpoint after each record processed. If the crawl fails and is restarted the crawler will restart from the latest checkpoint.
Checkpoints can be deleted by using the Advanced update link of the Update tab, from the Admin UI home page.
Updating TRIMPush Collections
The TRIMPush crawler attempts to impersonate the gather user so that updates can be triggered from the Admin UI. In some cases this impersonation can fail (depending on the service user that runs Funnelback, and on the Windows Domain configuration). If so the update will have to be started from the command line, either as an Administrator or as the gathering user using the runas /user:DOMAIN\User ... command.
Record types and classification security
A separate utility will collect the available record types and classifications from the TRIM repository in order to enforce security based on these items.
This utility must be run regularly so that the available record types and classifications are kept in sync. The usual way to do it is to setup a post_update command on the TRIMPush collection so that they get exported every time the TRIMPush collection is updated, usually on a daily basis. When you create a new TRIMPush collection, the post_update command is automatically configured with: post_update_command=$SEARCH_HOME\wbin\trim\Funnelback.TRIM.ExportSecurityInfo.exe $COLLECTION_NAME
This will place the record types and classifications security files inside the live/databases/ folder of the target Push collection, as it's the Push collection that will be queried.
Extra collection options
There are many additional settings that affect the TRIMPush crawler adapter which can be accessed via the collection configuration interface.
Default live links
The live links provided by Funnelback can be set to to give the user copies of the documents in TRIM (Documents) or a 'TRIM reference' capable of launching the TRIM client and taking the user to the record in question (References). Use the 'References' setting if all of your searchers will have the TRIM client installed on their machines. You must use the 'References' setting if you wish to display results based on records without electronic documents.
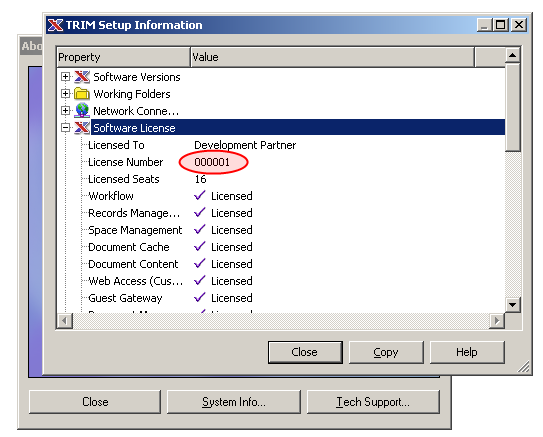
TRIM license number
The TRIM license number is required when references are used as live links as it will be used to generate valid references. This number can be found using the TRIM client (Help->About TRIM, System info., Software License->License number) as shown below. The leading zeros can be omitted.
Statistics dump interval
The interval (in seconds) at which statistics will be written to the monitor.log file name. Reducing this interval will produce more fine grained monitor information and graphs, but might induce overhead.
Progress report interval
The interval (in seconds) at which the crawler will update the current progress status that is display on the Admin home page.
Web server work path
TRIM needs a temporary folder where to extract attachments during the crawl, the location of this folder can be set there. If not set, the default will be used (Usually C:\HPTRIM\WebServerWorkPath). This folder can grow quite large during a crawl.
Properties black list
List of record properties that should not be extracted (See below)
User fields black list
List of user fields that should not be extracted (See below)
Properties and user fields
By default the TRIM crawler will try to extract as much properties and user fields as possible for all records. In some circumstance skipping some properties and user fields might be relevant:
- Some properties are expensive to compute, such as the ones involving dates calculations. Skipping those properties will significantly improve the crawler speed.
- Some properties should not be displayed in search results, or are not accessible by the crawl user.
- Some properties are irrelevant to search on.
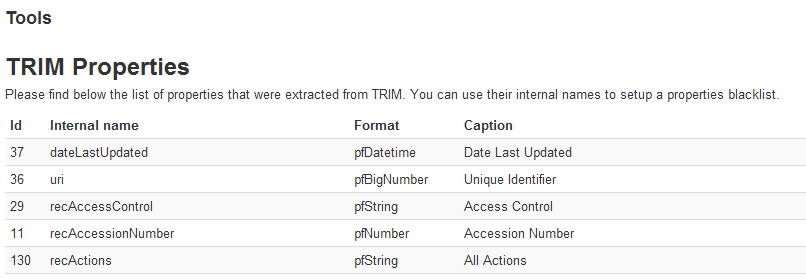
The Properties black list and User fields black list controls which property will be ignored during the crawl. Each list must contain one property per line, using the internal property name. To find out which property names are available the Collection tools link from the Administer tab can be used:
Serving search results
The search results will be served from the Push collection, as it's the one that holds all the gathered data. Some TRIM settings might need to be replicated on the Push collection to have results served properly, such as trim.workgroup_server and trim.database. See the Push collections section for additional details.