Web collections
Introduction
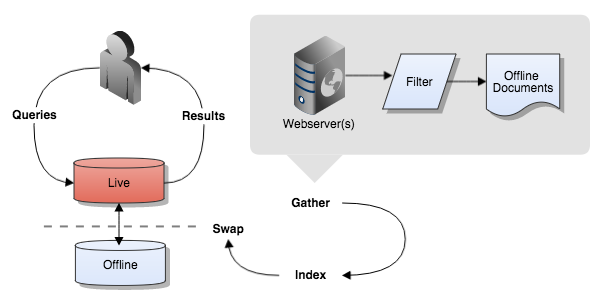
A web collection is a collection of documents obtained from one or more web sites. Web collections contain HTML, PDF and Microsoft Office files that are gathered using a web crawler which discovers content by following the links it finds.
In order to avoid crawling the entire Internet the crawler uses a number of configuration options to determine which links it will follow and what web sites or domains it should limit its crawl to.
Web collection basics
The web crawler works by accessing a number of defined URLs in the seed list and extracting the links from these pages. A number of checks are performed on each link as it is extracted to determine if the link should be crawled. The link is compared against a set of include/exclude rules and a number of other settings (such as acceptable file types) determining if the link is suitable for inclusion in the index. A link that is deemed suitable is added to a list of uncrawled URLs called the crawl frontier.
The web crawler will continue run taking URLs off the crawl frontier, extracting links in the pages and checking the links against the include/exclude rules until it runs out of links in the crawl frontier, or an overall timeout is reached.
Include/exclude rules
The crawler processes each URL it encounters against the various options in collection.cfg to determine if the URL will be included + or excluded − from further processing:
+crawler.protocols+include_patterns+crawler.accept_files−exclude_patterns−crawler.reject_files
Example
Assuming you had the following options:
include_patterns=/red,/green,/blue
exclude_patterns=/green/olive
Then the following URLs will be included or excluded...
| URL | Success? | Comments |
|---|---|---|
| /orange | FAIL | fails include |
| /green/emerald | PASS | passes include, passes exclude |
| /green/olive | FAIL | passes include, fails exclude |
Regular expressions in include/exclude patterns
To express more advanced include or exclude patterns you can use regular expressions for the include_patterns and exclude_patterns configuration options.
Regular expressions follow Perl 5 syntax and start with regexp: followed by a compound regular expression in which each distinct include/exclude pattern is separated by the | character. Regex and simple include/exclude patterns cannot be mixed within a single configuration option.
An example of the more advanced regexp: form is:
exclude_patterns=regexp:search\?date=|^https:|\?OpenImageResource|/cgi-bin/|\.pdf$
which combines five alternative patterns into one overall pattern expression to match:
search?date=for example, to exclude calendars.- HTTPS urls
- Dynamic content generated by URLs containing
?OpenImageResource. - Dynamic content from CGI scripts.
- PDF files.
Note: regex special characters that appear in patterns must be escaped (e.g. \? and \.):
include_patterns=regexp:\.anu\.edu\.au
Excluding URLs during a running crawl
The crawler supports exclusion of URLs during a running crawl. The crawler.monitor_url_reject_list collection.cfg parameter allows an administrator to specify additional URLs patterns to exclude while the crawler is running. These URL patterns will apply from the next crawler checkpoint and should be converted to a regular exclude pattern once the crawl completes.
Creating a web collection
Web collections require at a minimum a set of seed URLs and include/exclude patterns to be defined when setting up the collection.
To create a new web collection:
- Select 'Create collection' in the admin home page's top navigation bar.
- Enter the required details, including a group id, a collection id (eg.
example-organisation-web) to identify the collection. - Select "web" as the collection type
- Select a license for the collection and configure the collection's ownership
- Click the 'Create Collection' button, which creates the collection and navigates to the main configuration screen.
- Enter a set of start URLs and save them.
- Enter include and exclude patterns and save them.
- Customise any other requried settings.
- Return to the admin home page and update the collection.
Web crawler configuration
Web crawler logs
The web crawler writes a number of log files detailing various aspects of the crawl. See: web crawler logs