Collections: overview
A collection is a set of data that has been gathered from a data source, indexed and made available for searching. Collection types are based on their data sources:
Collection types
web
A web site or set of sites. The data is gathered using HTTP, or HTTPS, and plain text is extracted from binary document types such as MS-Word and PDF.
push
A collection where data is 'pushed' into the index through an API rather than being gathered by Funnelback.
meta
This is a grouping of one or more collections to provide querying over all data in the collections.
filecopy
A file-system. The data is gathered by copying files and the text is extracted from binary documents.
database
A database. The data is gathered using a JDBC driver to connect to the database and selecting one or more tables. The data is stored locally as XML.
directory
A directory (generally of people). The data is gathered using a JNDI driver to access and ActiveDirectory or LDAP directory. The data is stored locally as XML.
trimpush
A TRIM / HP Records Manager collection that can be searched while it's crawled.
matrix
A collection specifically designed for searching content from the Squiz Matrix CMS.
custom
A collection where data is gathered by a custom script.
A collection where data is gathered from Facebook.
flickr
A collection where data is gathered from Flickr.
A collection where data is gathered from Twitter.
youtube
A collection where data is gathered from YouTube.
slackpush
A collection where messages and files from Slack are processed and forwarded to a Push collection.
local
A local file-system. The data is not gathered, but indexed in place.
Populating a collection
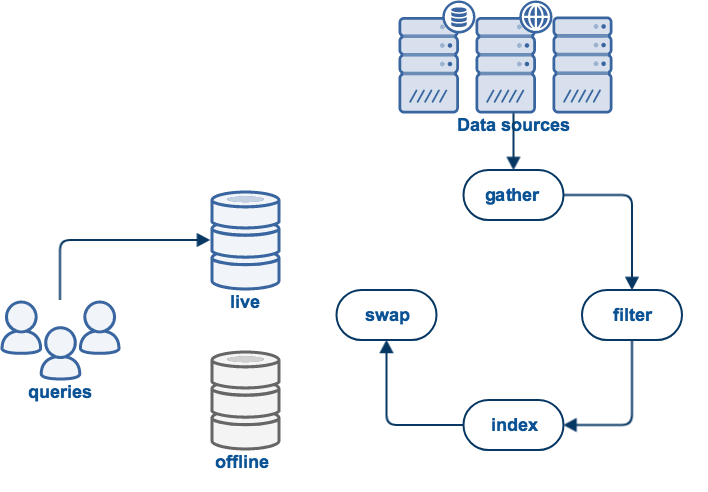
A collection is populated in the following order:
- The data is gathered. For example, if it is a web collection the web sites will be crawled to download all HTML files and other documents.
- All "binary" documents are filtered to extract plain text. For example, PDF files will be processed to extract the text.
- The documents will be indexed: word lists and other information will be processed into Funnelback indexes. The index is then used to answer user queries.
All of this work occurs in an offline area to prevent disrupting the current live view which is being used for query processing. If the update process completed successfully, the live and offline views will be swapped, making the new indexes available for querying.
Manage collections
For details on how to manage Funnelback collections, see the following: