Updating collections
Steps
Updating a collection occurs in five steps:
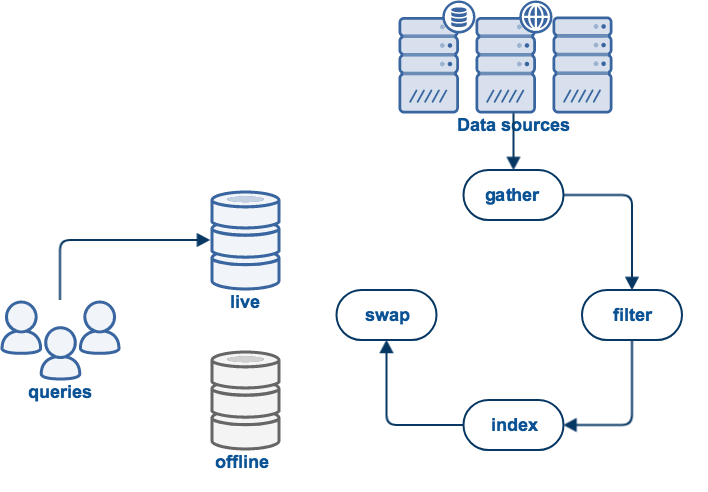
gather
Is the process of collecting the data to be indexed. For example, web collections will use a web crawler to download web pages and follow links found in these pages.
filter
Binary documents, for example PDF, need to be processed to extract the plain text.
index
Process the documents which were gathered and indexes words, phrases, HTML anchor text, and so on.
report
Scan over the documents that have been gathered and filtered, producing reports on their content.
swap
All of the above work occurs in an offline view to prevent disrupting the current live view which is being used for query processing. If the update process completed successfully, the live and offline views will be swapped, making the new indexes available for querying.
Performing an update
From the "Update" tab on the administration home page you can update a collection in three ways:
- "Update this Collection": start a full update right away (no further confirmation required)
- "Schedule Automatic Updates": Scheduling updates to occur at particular times
- "Start Advanced Update": specify a particular type of update
Update types
The advanced update page (shown below) provides the ability to initiate a full update or restart the update process from any stage which is relevant for the chosen collection.
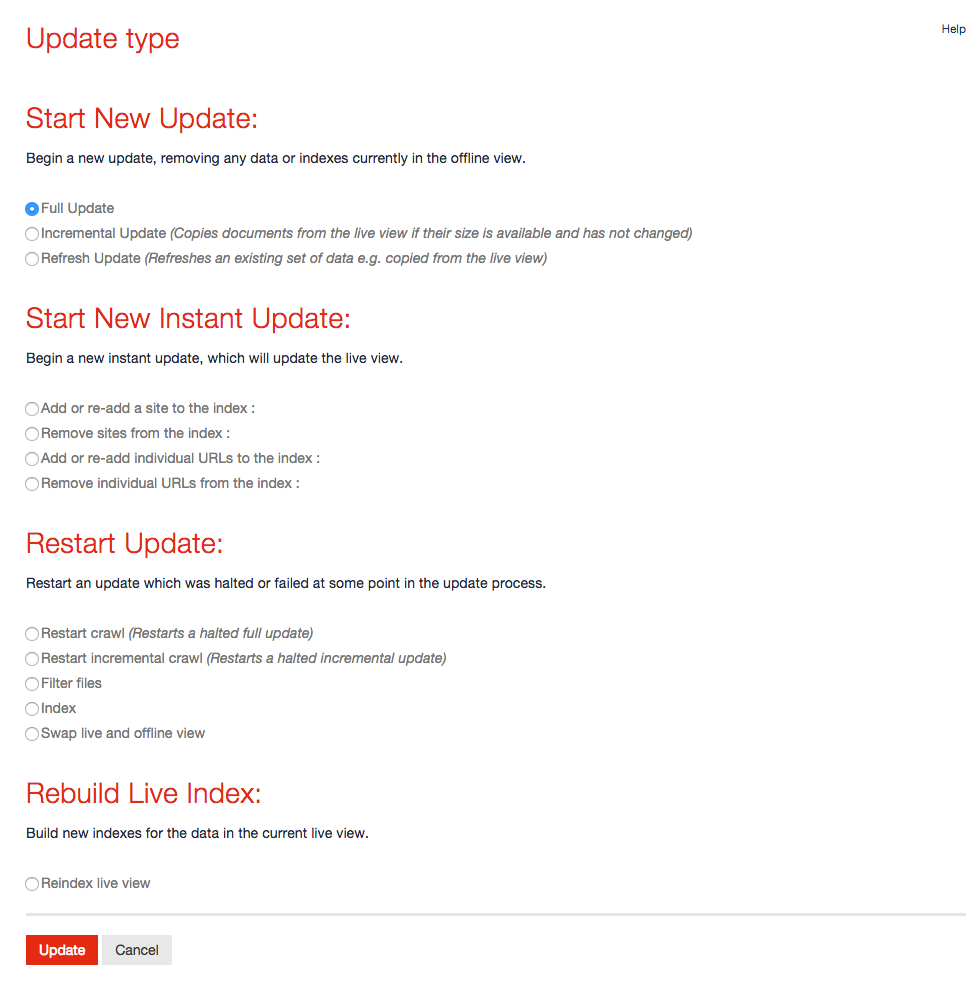
The available options are:
Full update
Performs a complete gather (i.e. web crawl, database export etc) from scratch. Documents will be gathered, filtered and then indexed before they are swapped into the live area. This is the default setting.
Incremental update (Web/Database collections only)
Performs a complete web crawl, but rather than downloading all documents, the web crawler will check against the previous crawl, and if the document is unchanged, it is not re-downloaded. When crawling has completed, new documents are filtered and all documents are indexed before being swapped into the live area.
Refresh update (Web collections only)
This is similar to an incremental crawl. It operates by copying all data from the live view to the offline view and then crawling on top of that. The crawl would then be configured to crawl less than the usual full or incremental crawl, so that it "refreshes" a subset of the data. URLs which generate an exception (e.g. "404 Not Found") during the crawl will be removed from the store. For some store types at the end of the crawl the list of crawled files (manifest) is merged with the previous manifest to ensure that all files are indexed in crawl order. This update type is different to an "Instant Update" in that it still uses the (potentially large) list of include/exclude patterns for the collection, rather than a restricted list defined for an instant update.
Add or re-add the specified site/directory (Instant update) (Web/Filecopy collections only)
Performs a limited crawl and re-index restricted to the start URL or directory and include/exclude patterns provided. This option is for including new content into an index as quickly as possible, without taking as long as a full update might take to complete. It is strongly recommended that full updates still be used regularly.
Remove the specified site/directory (Instant update) (Web/Filecopy collections only)
Removes the specified site or directory from the index, so that resources within this site or directory will no longer be returned as search results. (Note that this works on a URL or path prefix and may not contain any spaces)
Add or re-add the specified URLs/files (Instant update) (Web/Filecopy collections only)
Performs a crawl and re-index of the specified URLs or files only (i.e. links will not be followed). This option is for updating important pages in the index quickly, without taking as long as a full update might take. It is strongly recommended that full updates still be used regularly.
Remove the specified URLs/files (Instant update)
Removes the specified URLs or files from the index, so that these items will no longer be returned as search results.
Restart crawl (Web collections only)
Restarts a full web crawl from the latest checkpoint. When crawling has completed, the documents are filtered and indexed before being swapped into the live area. You can use this to resume a halted or crashed crawl from the most recent checkpoint.
Restart incremental crawl (Web collections only)
As above, but restarts the web crawl as an incremental update rather than a full update.
Filter files
Extracts textual information from specific file formats such as PDF and Microsoft Office documents. Afterward, the documents are indexed and swapped into the live area.
Index
Indexes the existing offline data and then swaps the live and offline views. You can use this to index data from an update that has crashed or been halted.
Swap live and offline view
Swaps the live and offline views. This activates the offline view and deactivates the live view. You can use this to restore the previous view in the event that one of the above update types proves undesirable or if you wish to revert to the previous crawl and index.
Re-index live view
Indexes the existing live data and then activates the new indexes directly. This can be used to bring indexing configuration changes into effect directly without re-gathering data.
Scheduling updates
Funnelback provides two scheduling interfaces, one oriented towards scheduling collection updates for a Linux platform, and one oriented towards scheduling collection updates for a Windows system.
Stopping a collection update
A collection cannot be edited, updated or deleted while an existing update process is already in progress. However, a collection update can be stopped before it has completed.
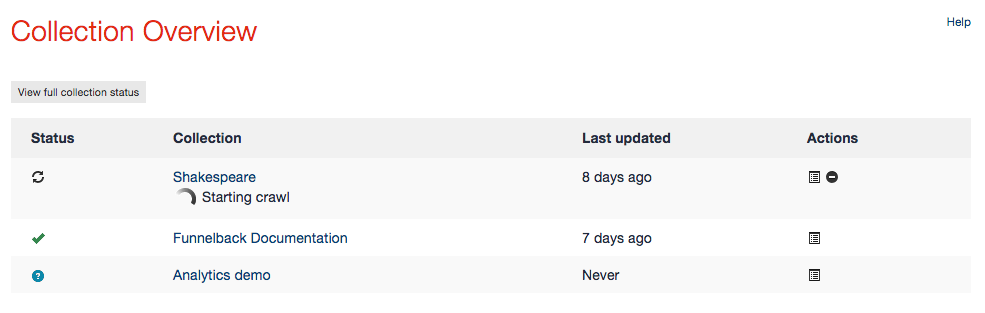
This can be done by going to the "Collection Overview" panel on the administration home page and clicking on the "Stop Update" icon (black circle with white line) beside the collection being updated. This will take you to a page asking you to confirm that you wish to stop the update.
If you confirm the action the home page will display a message stating that the update is being stopped. Stopping an update may take a while, as the gathering component has to complete its current tasks first and properly flush the data on disk.
Lock files
Once a collection update has been requested, Funnelback creates a collection-specific lock file in the collection's data directory (e.g. $SEARCH_HOME/data/<collection>/log/<collection>.lock) to prevent another update of the same collection being requested while the first is in progress. This lock file is automatically removed when an update succeeds or fails.
In certain rare circumstances such as a machine crash, the lock file may not be removed and prevent subsequent updates. See Funnelback troubleshooting for more information.