Preparing content for knowledge graph and configuring entities
Introduction
Entities (or nodes) must be defined in the datasource collections before a knowledge graph can be created. This involves identifying the URLs that are suitable for entities and ensuring that they have appropriate metadata defined in the index.
Identify candidate URLs
Examine the URLs available within each datasource collection and identify those that correspond to entities, and what metadata will be used to describe the entity.
For each of the entities consider:
- The entity type.
- The set of unique values that can be used to identify the entity.
- Other attributes should be displayed for this node when it is viewed in the knowledge graph.
- Useful relationships with other entities.
Populate the node metadata fields
Items that are suitable for entities must have two metadata fields defined to be considered as an entity within the knowledge graph. The metadata must be mapped to the following metadata classes:
FUNkgNodeLabel: Defines the entity type and provides a means to group related entities e.g. people, courses, documents. Note: The node label will automatically be converted to lower-case, have any leading numbers removed, and have any characters other than a-z, 0-9, underscores (_) and spaces removed. Funnelback knowledge graph supports a single entity type for any given entity.FUNkgNodeNames: Specifies the set of unique names which are used to identify an instance of an entity. e.g. for a person this might be 'FirstName LastName', 'logon', 'email address', 'LastName, FirstName'. Metadata field content is split into separate values following the standard metadata splitting rules in Funnelback.
Both FUNkgNodeNames and FUNkgNodeLabel be mapped using the metadata mapping interface.
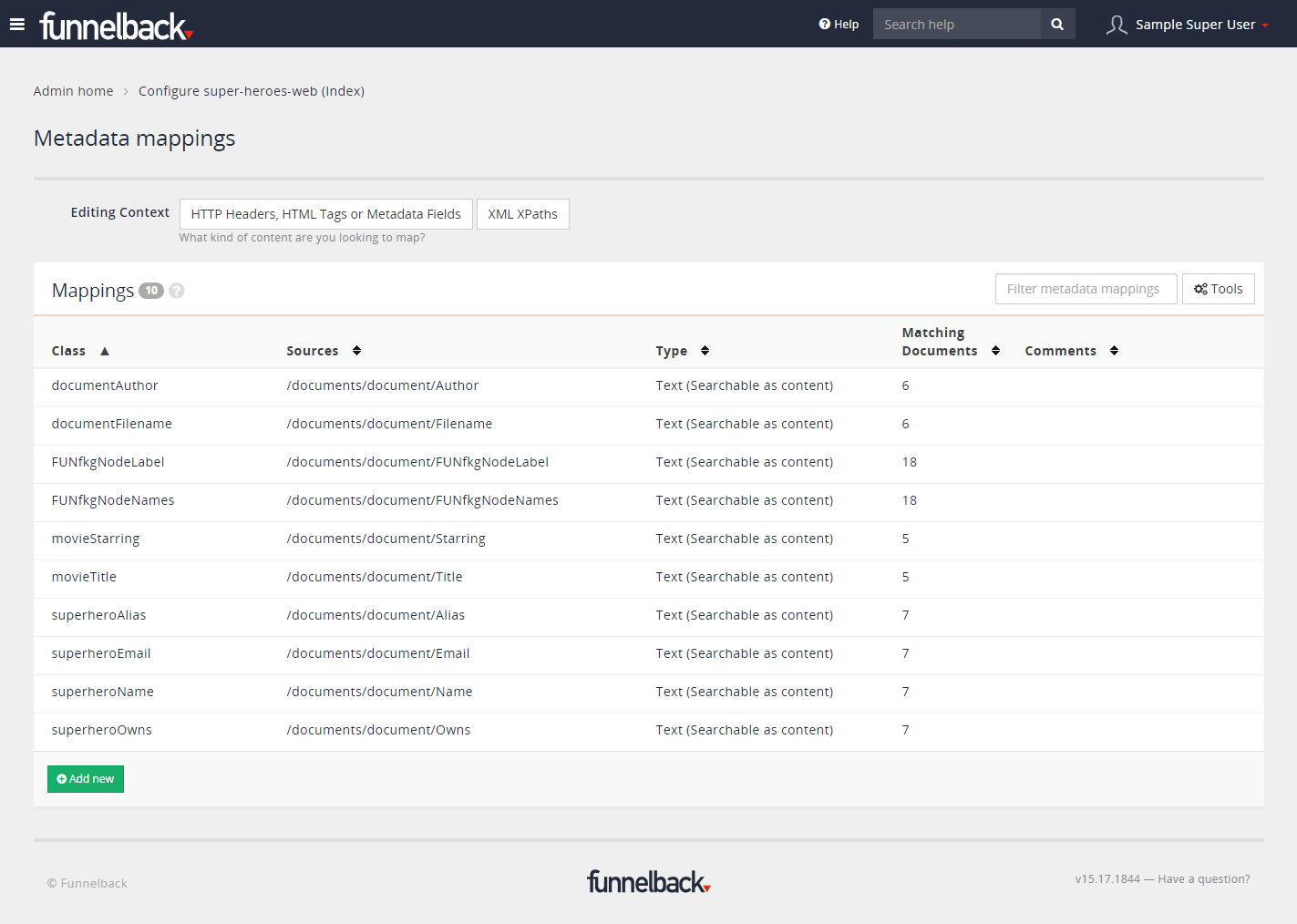
Other attributes that will be displayed in the knowledge graph must also be mapped. All the mapped metadata fields will be available for use when defining relationships and when configuring the knowledge graph interface. Any changes to the metadata mappings requires the Funnelback search index to be rebuild and then knowledge graph to be updated.
The metadata can be associated in a number of ways:
- direct mapping: if the metadata exists in the source data in an appropriate format the fields can be mapped directly to the
FUNkgNodeLabelandFUNkgNodeNamesmetadata classes. - external metadata: by defining
FUNkgNodeLabelandFUNkgNodeNamesmetadata within the external metadata file. - builtin filter: such as the metadata scraper
- custom filter: that implements custom logic to extract and produce the metadata in the correct format.
There are some issues with the direct mapping of existing metadata fields using the metadata mapping interface:
- Metadata fields can only be mapped to a single metadata class in Funnelback. This means that any field mapped to a node metadata class can’t be used in other metadata classes.
- If knowledge graph is being applied to an existing collection remapping fields may break other functionality such as templates, or adversely affect the ranking (e.g. if the title metadata is mapped to node metadata)
Preparing the source content for Funnelback
Add suitable metadata
If you have control of the source content the ideal way to prepare it for Funnelback is to ensure that each URL or item that is a candidate for an entity has custom fields for the entity type and names, and that anything else suitable for entity properties is defined as in page metadata.
e.g. if person records are created from HTML staff pages on an intranet ensure that an individuals page have in-page metadata defined similar to:
<meta name="entity.type" content="person"/>
<meta name="entity.names" content="John Smith|Smith, John|J Smith|jsmith@company.com|jsmith"/>
<meta name="firstname" content="John"/>
<meta name="lastname" content="Smith"/>
<meta name="email" content="jsmith@company.com"/>
<meta name="description" content="John Smith is the director of operations and is responsible for the day to day running of the company."/>
<meta name="phone" content="02 9876 5432"/>
<meta name="officelocation" content="Parramatta"/>
Fields containing multiple values should ideally be delimited with a vertical bar character.
Add noindex tags
For best results ensure Funnelback noindex tags are added to the content template to exclude areas of the page that should not be indexed as content. e.g. on a web page wrap headers, footers and navigation in noindex tags.
This is important as the automatic mentions relationships are detected in the item's indexable content.
See: Controlling indexable content
Modifying and supplementing the data source
If it is not possible to change the source content there are some other options available.
- Use external metadata to inject metadata for specific URLs
- Use document filtering to manipulate the page content before it is indexed/
- Insert Funnelback noindex tags into the page content using filters.
External metadata
External metadata can be used to inject FUNkgNodeLabel values to quickly group related web documents without needing to modify the document source.
e.g.
www.example.com/books FUNkgNodeLabel:"product"
www.example.com/cds FUNkgNodeLabel:"product"
www.example.com/writers FUNkgNodeLabel:"author"
All documents under the books and cds paths will be created as product entities. Similarly, all documents under the writers paths will be created as author entities.
Document filters
Document filters implemented in groovy can be used if more complicated actions are required where data needs to be modified or sanitised so that it is in the correct format.
Note: writing custom filters (or using the metadata scraper) to extract metadata from page content should be avoided as any changes to the underlying code structure of the page can potentially break the extraction of the metadata, which in turn will break the knowledge graph. However if you can ensure that this will not change, or are happy to carry the risk of the extraction breaking then this is a valid approach that enables a graph to be added on top of an existing content source.
There are two existing filters that may assist with adding metadata:
- Metadata scraper: If the metadata doesn’t exist (e.g. the entity type might be inferred by the collection so that every item in the collection is of a particular type) it needs to be added as metadata to the items. External metadata may enable this but it relies on identifying the items via a left matched URL string. Alternatively metadata can be added via filters such as the metadata scraper, or custom filters that implement custom logic. See: metadata scraper filter
- KGMetadata: There is an unofficial filter available in GitHub that can be used to clone metadata for use with knowledge graph. See: KGMetadata filter
- Custom filters: can be written to parse and modify the content before it is indexed. Use a Jsoup filter for processing of HTML documents if possible as this is a more reliable way of processing HTML.
More information can be found on the writing filters page.
Inserting noindex tags into the content
Funnelback noindex tags can be inserted into the content using:
- Inject no index filter
- from a custom filter (see above section on custom filters)