Content auditor
Introduction
The Content Auditor is a tool which allows a collection administrator to rapidly gain an understanding of the content of a site or set of sites, with a particular focus on metadata.
Accessing Content Auditor
You can access the Content Auditor from the administration UI's analyse tab, or directly at:
/s/content-auditor.html?collection=(COLLECTION_ID)
Note that the Content Auditor is available only via https with a valid Funnelback administration account, and on the same port as the Funnelback administration interface.
Using Content Auditor
Content Auditor is available for every Funnelback collection from the Admin UI's "View Content Auditor" link, and by default provides an overview of some common metadata.
Content Auditor provides a range of sub-reports arranges in tabs, and options to navigate through your content either by keywords (i.e. any valid Funnelback search query), but filtering the report based on URL prefixes, and by filtering based on any metadata value shown within the Content Auditor interface.
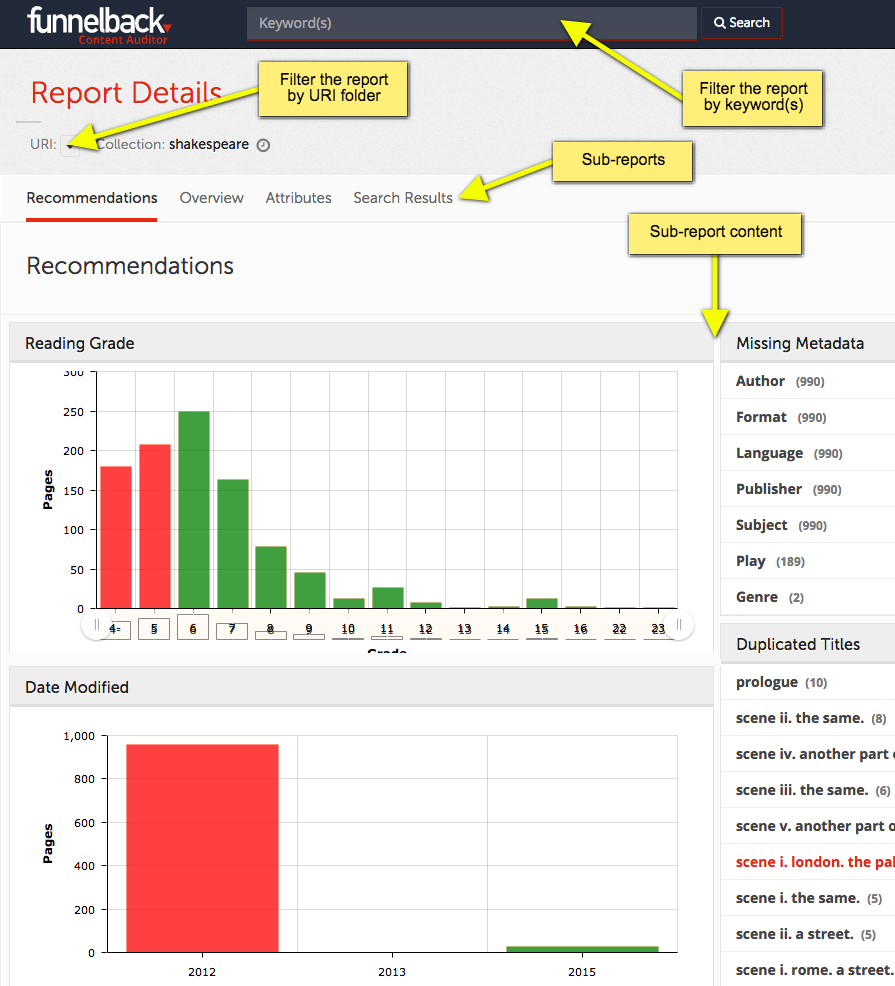
The first tab within Content Auditor, as shown above, provides a range of 'recommendation' reports which are associated with common content best practices. These reports are as follows:
Reading grade
The reading grade report measures how easily documents are to read, based on the Flesch Kincaid grade level measure, which relates roughly to the number of formal education require to understand the document.
While this measure is an heuristic rather than an exact measurement, it may be useful in ensuring that website content is written at an appropriate level.
The range of 'green' grade levels can be configured with the ui.modern.content-auditor.reading-grade.lower-ok-limit and ui.modern.content-auditor.reading-grade.upper-ok-limit parameters
Missing metadata
The missing metadata report identifies documents for which no metadata of a given type occurs. This may be helpful in enforcing content policies requiring certain types of metadata to be available in all documents within certain areas.
Duplicate titles
The duplicate titles report identifies documents for which the given title is also used by other documents. Duplicated titles can make websites and search result pages less useful, since they lack sufficient context for a user to understand what page is being shown.
Note - For this report to be used with documents which are not originally HTML or filtered to HTML (such as XML records), a copy of the title metadata to be considered must be mapped to the FunDuplicateTitle metadata class.
Date modified
The date modified report presents a chart of when documents were last modified, based on metadata within the documents, and hence may be helpful in identifying documents which should be updated or reviewed.
The allowable document age before it is marked in red can be configured with the Ui.modern.content-auditor.date-modified.ok-age-years setting.
Response time
The response time report provides a chart of the time taken by Funnelback's web crawler to load each document, which may help to identify documents, sections or entire sites where response time is in need of improvement.
Undesirable text
In its default configuration, the undesirable text report provides information on documents which contain common misspellings, which allows such typos to be rapidly found and corrected.
This report may be configured through the filter.jsoup.undesirable_text-source.* collection configuration setting, which allows for organization-specific lists of undesirable terms, such as outdated product names, to be included within the set to be identified.
Duplicate content
The duplicate content report shows documents for which the content (or if configured, some metadata) is duplicated by other documents. Duplicated content makes site more difficult to navigate, and may also be penalized as a ranking factor by some search engines.
The ui.modern.content-auditor.collapsing-signature configuration parameter can be used to configure exactly what parts of documents are considered for duplication.
Other Content Auditor reports
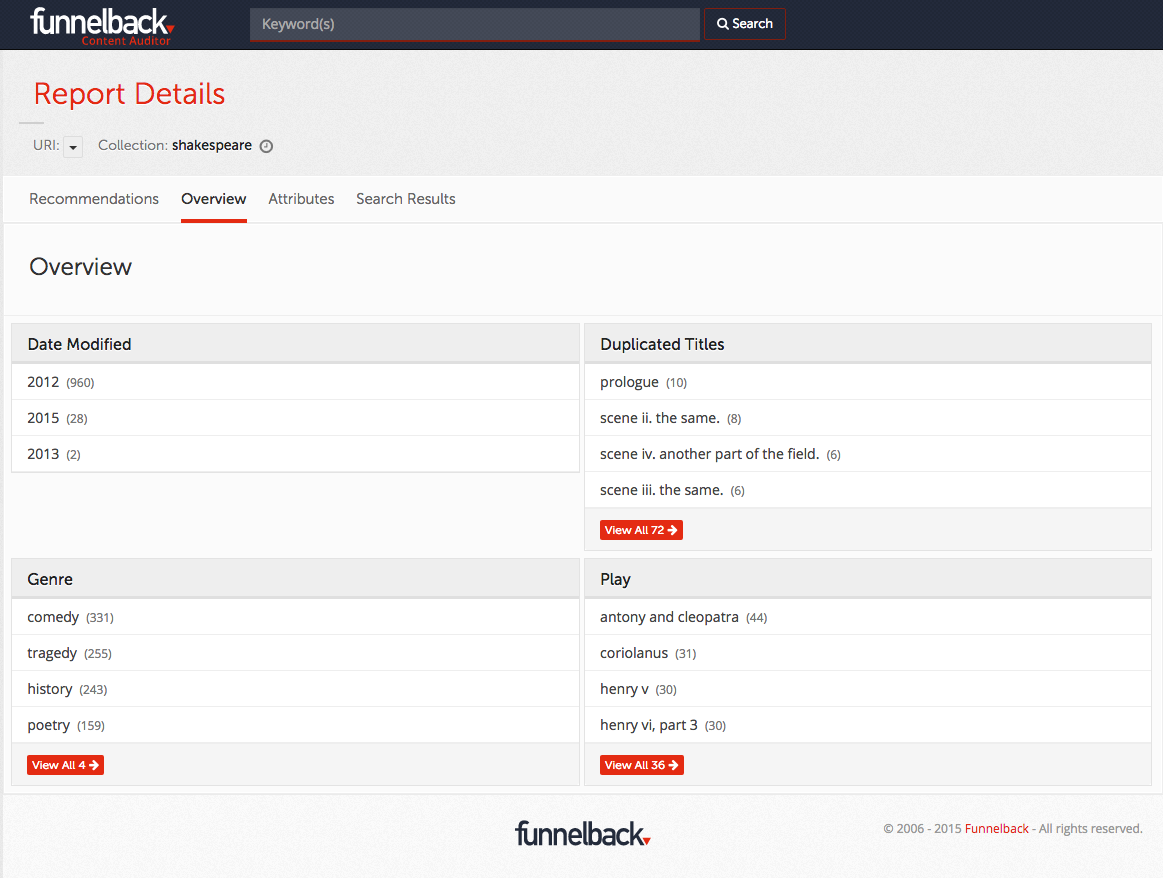
The overview tab of content, shown below, provides a snapshot of the top metadata within each configured facet of the collection, showing the most common four entries for each. Each category provides a link which can be used to 'drill down', allowing content audit reports to be created for chosen subsets of content. The example below shows a number of facets for a simple example collection.
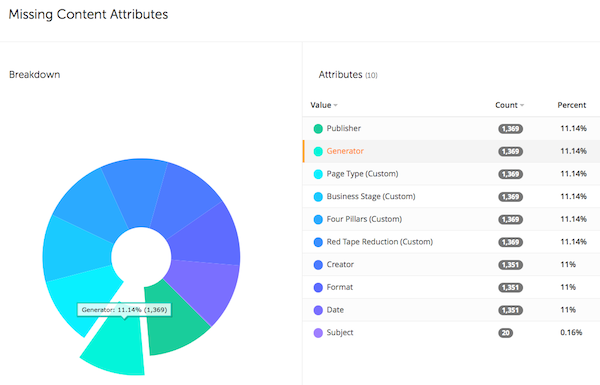
From the overview page, you can navigate to the attributes tab which provides a complete list of metadata values found in each facet, and estimates of the count of matching documents. Again, clicking on one of the values in the list will restrict subsequent reports to documents containing that metadata value.
The third Content Auditor tab provides a list of currently matching search results, with easy links through to various Funnelback tools, as well as to CSV exports of the result list.
The final tab, shown in the example above with the number 15 beside is, shows any sets of duplicate content which was encountered within the collection, and allows this duplicate content to be shown as a result list.
Note also that the search box at the top of the content auditor interface allows auditing reports to be restricted based on any Funnelback query, in addition to the drill-down options.'
Once a facet category has been selected, the constraints applied are displayed by Content Auditor as in the image below.

The small 'x' links to the right of each constraint allow that constraint to be cleared if needed.
Configuring Content Auditor
Content Auditor can be configured in a number of ways to provide relevant reports for different data sets. Most configuration occurs via the collection.cfg and profile.cfgsettings with the ui.modern.content-auditor prefix.
In addition to the settings for specific reports noted above, following factors can be configured:
- The metadata to be used for display
- The metadata to be used for and drill-down
- The number of documents to display, and the number to examine for duplication
- The number of drill-down categories to display in the overview
- Classifying textual vs non-textual documents
- Facets to display in the Marketing Dashboard
If necessary, further customization can be performed though user interface hook scripts specifically targeting Content Auditor.
Note that any query based facets configured for a collection will also be displayed within Content Auditor as metadata to analyse.
Batch reports for specific properties of content pages which are not represented in existing metadata can also be created and included by developing groovy filters to check properties and create metadata to be used for auditing/reporting.